Cyclistic Bike Share Analysis
Overview
This project is my capstone case study for the Google Data Analytics Professional Certificate program. During it, I analyzed trip-level data from the Chicago based bike share service Divvy in the context of a fictional business called Cyclistic. Acting as a data analyst on a marketing team, I was tasked with answering the question: How do annual members and casual riders differ in their use of Cyclistic bikes?
Answering this question required me to engage in the entire data analytics process. The milestones of this project include:
- Determining the business task and the set of deliverables which were expected of me as a data analyst.
- Gathering the correct data sets which would be required to answer the core question.
- Using the R programming language with R Studio to clean, process, analyze, and visualize my data.
- Making sensible business recommendations based on the findings of my analysis.
To view the full source code of this project see the Kaggle Notebook.
The Scenario
You are a data analyst working for a Chicago based bike share company called Cyclistic. The company has a fleet of almost 6,000 bicycles that can be retrieved from and deposited at any of the approximately 700 stations spread throughout the city. Their pricing plan offers single-ride passes, full-day passes, and annual memberships. Customers who have annual memberships are referred to as “annual members”. All other customers are called “casual riders”.
The company’s financial analysts have determined that annual members are significantly more profitable than causal riders. Your manager, the director of marketing, believes that maximizing the number of annual members is the key to the company’s growth. Therefore, her goal is to design a marketing strategy which will convert casual riders into annual members.
To do this, the marketing team needs to answer three key questions:
- How do annual members and casual riders differ in their use of Cyclistic bikes?
- Why would a casual rider buy a Cyclistic annual memberships?
- How can Cyclistic use digital media to influence casual riders to become members?
Our manager has tasked us with answering the first of these three questions: How do annual members and casual riders differ in their use of Cyclistic bikes?
Findings
Through my analysis I was able to find several differences in the behavior of annual members and casual riders. Firstly, I found that casual riders are responsible for significantly less of the total number of bike share trips. In fact, casual riders accounted for only 21.8% of total bike trips. Meanwhile, usage by annual members was over three times higher and accounted for 78.2% of total bike trips.
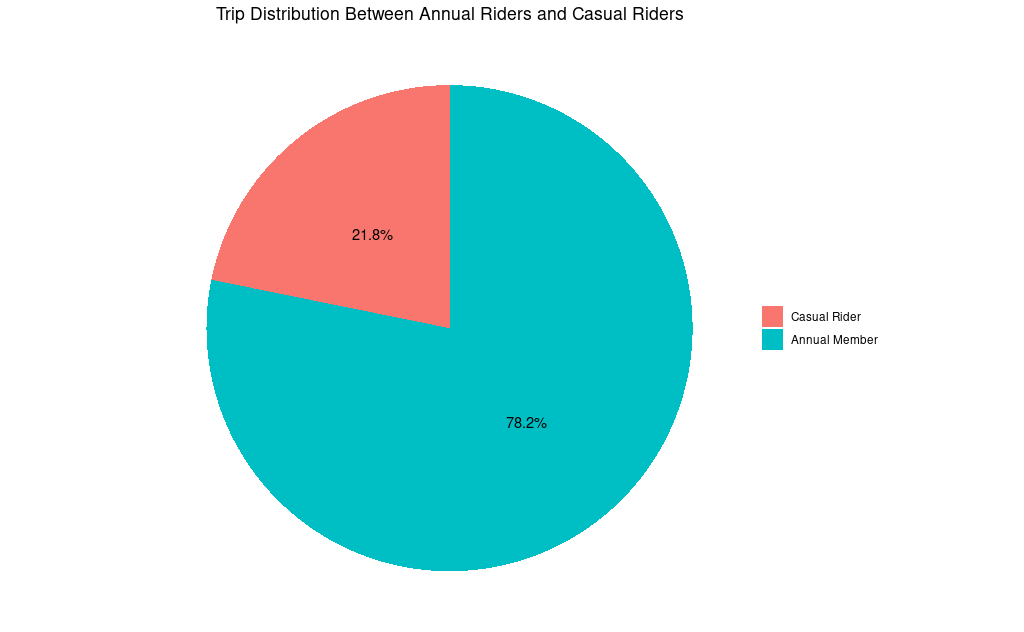
There were also differences in when the two groups use the bike share service. Throughout the year, usage between the two groups was quite similar. Both groups go on less bike trips in the Winter and late Fall months. And, both groups go on more bike trips in the Spring and Summer months with peaks around August.
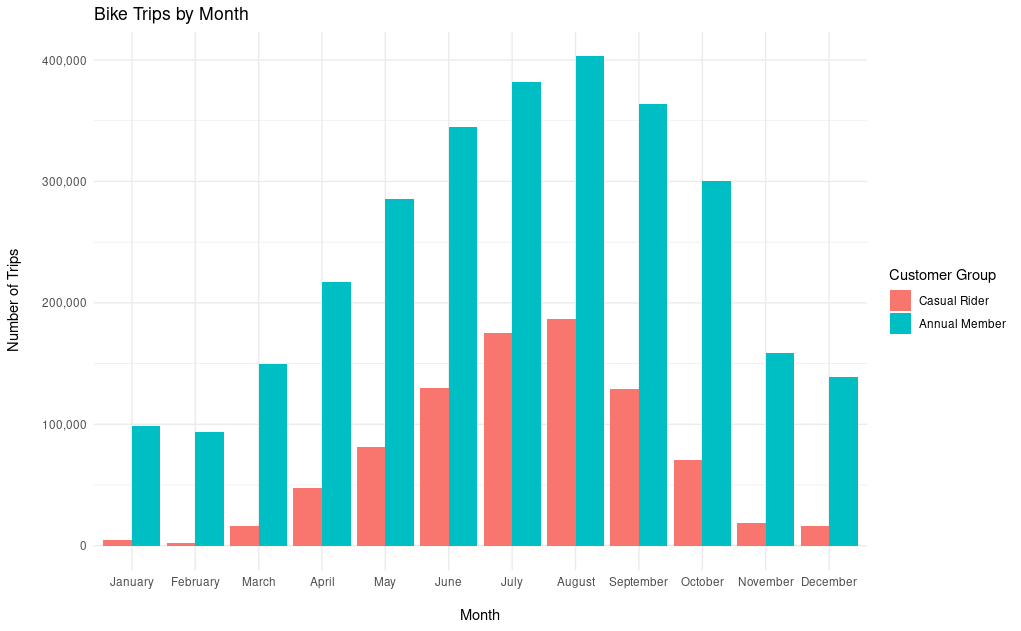
However, bike share usage by annual members is several times higher in Winter compared to casual riders. In November, December, January, and February, bike share trips by casual riders are almost non-existent. This indicates that there is some fundamental difference between the people composing the casual rider group compared to the annual member group.
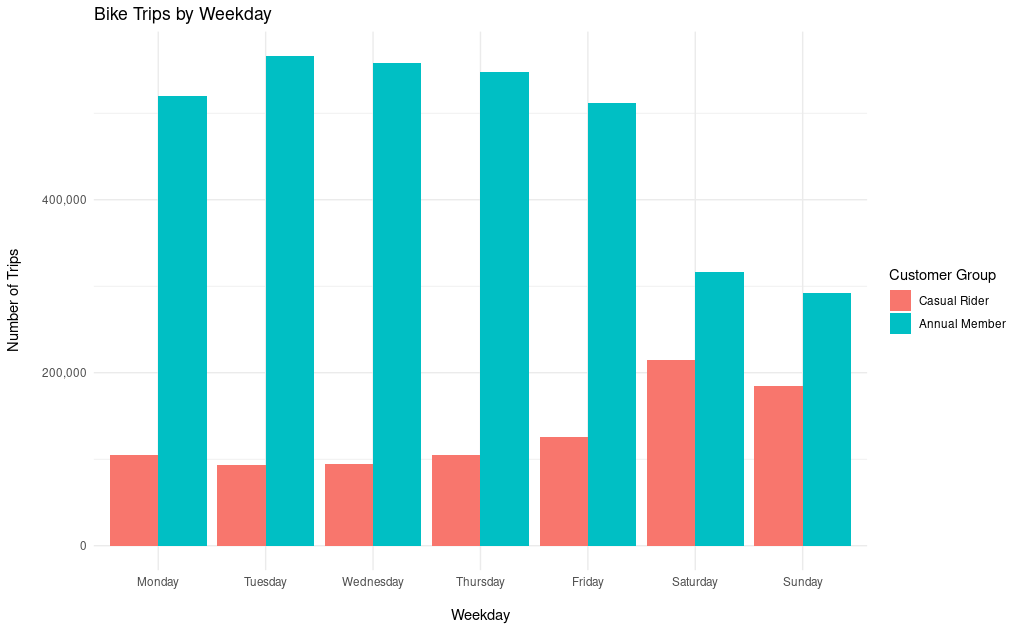
An analysis of which day of the week trips take place in each group gives us more insight. During the workweek, trips by casual riders are low. But, the number of trips they take rises on the weekend. The inverse is true for annual members. Annual members take many trips during the workweek. However, their usage drops during the weekend.
This could be explained in a number of ways. The most obvious is that the casual rider group is composed of more tourists than city residents. For example, the increase in trips by casual riders on the weekend could represent people coming into the city for weekend entertainment.
Additionally, the drastic fall in trips by casual riders during the Winter months could coincide with an overall decrease in tourism. The fact that trips by casual riders are extremely low in the Winter months, while trips by annual members remain relatively high, lends credence to the idea that the casual rider group contains less city residents.
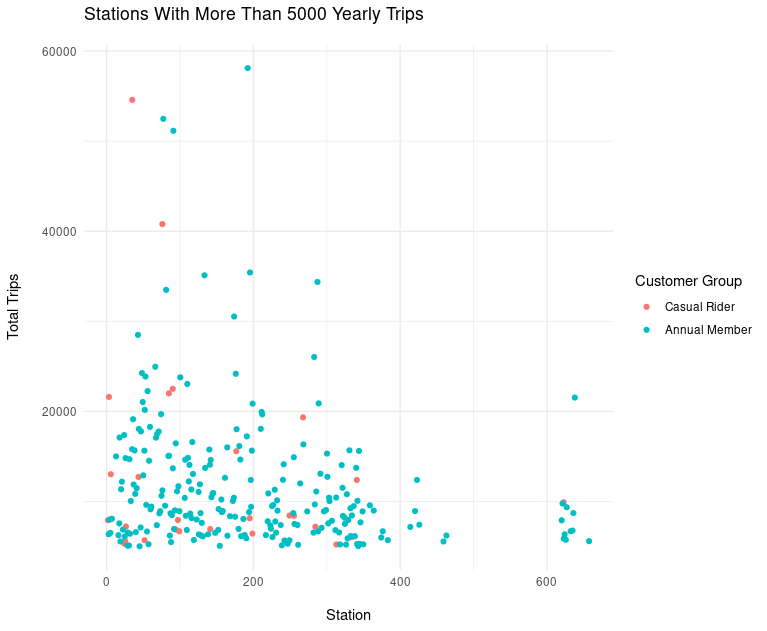
Investigating the overlap between which bike share stations each customer group uses also shows a fundamental behavioral difference.
In the above chart, we examine the trip totals by each customer group originating from stations with 5000 or more total trips. In other words, these are the most popular stations. As you can see, the most popular stations are not as popular with casual riders as they are with annual members.
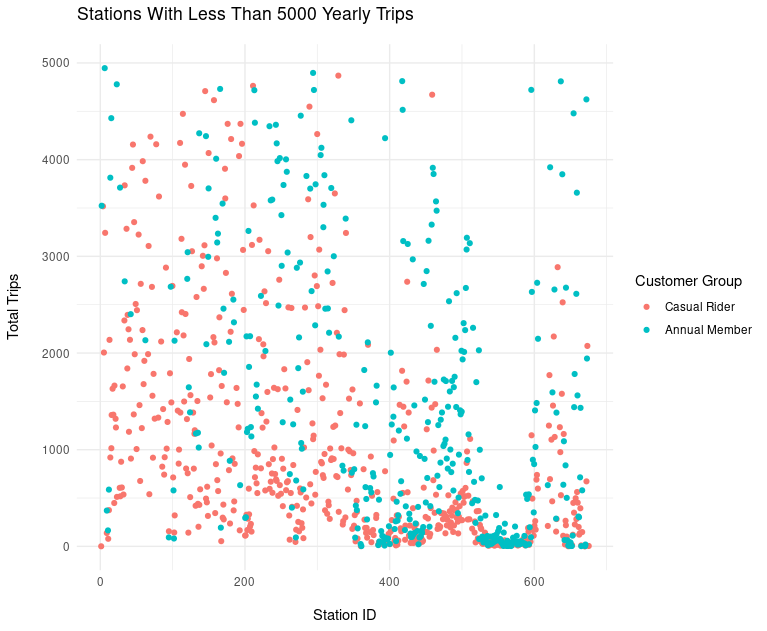
Likewise, if we examine stations with less than 5000 total trips, i.e. the unpopular stations, we find a greater degree of overlap. Additionally, there is a cluster of stations which are unpopular in both groups. This information might be help when deciding which stations to focus the marketing campaign upon.
Finally, there is one last descriptive element of our data worth noting. On average, annual members use their bike for just under 13 minutes, while casual riders use their for around 40 minutes.
Recommendations
Based on these findings, there are several recommendations to be made:
-
The marketing campaign should be limited to the Spring and Summer months. These are the months that recieve that greatest amount of activity from casual riders. The Fall months represent a sharp decline in bike share usage, and in the Winter months bike share usage is almost non-existent.
-
The marketing campaign should be intensified on the weekends. We know that casual riders tend to use the bike share more on the weekend than during the workweek. While usage during the workweek is fairly level in the casual rider group, it spikes on Saturday and Sunday, so it makes sense to spend more on marketing during this time period.
-
The marketing campaign should focus on stations popular with casual riders. We know from our analysis that the stations which casual riders use differ from annual riders. Targeting the top stations would result in targeting predominately existing annual riders. Instead, focusing on stations popular with casual riders is likely to be more effective.
-
Perform further information gathering on the casual rider customer group. Given the behavioral differences between casual riders and annual members, it seems likely that casual riders are fundamentally different in some way. The casual riders most likely to be converted to annual members are either frequents tourists or city residents who have not yet purchased an annual subscription. By finding out more about who the casual riders are as people, perhaps through a survey, we can better market the service to them.
Methods
This section contains the data analytics notebook which was a required deliverable for the capstone project. This section is more technical than the proceeding section, and serves as a record of the cleaning, processing, and analytic methods I used to arrive at the findings and recommendations shared above. Below you will find a more detailed explanation of the data used in this project, the challenges faced when cleaning and processing it, and the analytical methods used to arrive at my conclusions.
Gathering Our Data
The company’s internal data is broken down into quarterly chunks. We have access to CSV data from the first quarter of 2015 to the first quarter of 2020. Our task is to analyze how bike use differs between annual members and casual riders, so we are only interested in data that informs us about recent usage trends. Therefore, we will focus our analysis on the data from 2019 and 2020.
For this project I used the four quarters from 2019 and the first quarter from 2020 which can be downloaded here. Download the following zip files:
- Divvy_Trips_2019_Q1.zip
- Divvy_Trips_2019_Q2.zip
- Divvy_Trips_2019_Q3.zip
- Divvy_Trips_2019_Q4.zip
- Divvy_Trips_2020_Q1.zip
Each of these zip files contains a corresponding CSV file which contains the data needed for our analysis.
Note: The data we are using is provided by Divvy for public use.
Data Cleaning
Now that we know our business task and have the data, our next step is to clean and process the data so that it can be used for analysis.
We will start by loading our data files into memory.
In the code below, we load every CSV files in the file_paths list into a list of five data frames called data_files.
|
|
Our first goal in the cleaning process is to integrate the data for our five data frames into a single data frame. Before we can do this we must first review and verify the integrity of our data.
Upon first inspection of the loaded data it is clear that there are some inconsistencies that must be fixed. The Q1, Q3, and Q4 data sets for 2019 seem to be fairly consistent. Each data frame contains the following columns:
| Column Name | Description | Data Type |
|---|---|---|
| trip_id | An apparently unique number representing the trip | integer |
| start_time | The trip’s start time in an ISO 8601-like format. | character |
| end_time | The trip’s end time in an ISO 8601-like format. | character |
| bikeid | The ID of the bike used on the trip. | integer |
| tripduration | The time in seconds that the trip took. | character |
| from_station_id | The ID of the station the trip started at. | integer |
| from_station_name | The name of the station the trip started at. | character |
| to_station_id | The ID of the station the trip ended at. | integer |
| to_station_name | The name of the station the trip ended at. | character |
| usertype | The user’s type (Subscriber or Customer) | character |
| gender | The user’s gender (Male, female, or “”) | character |
| birthyear | The year the user was born. | integer |
The second quarter of 2019 has all the same types of data, but uses different column names. We will apply the column names from the first quarter of 2019 to all other quarters in 2019 to ensure consistent naming across the entire 2019 data set.
|
|
The first quarter of 2020 is a far more complicated case. Here is its structure:
| Column Name | Description | Data Type |
|---|---|---|
| ride_id | An apparently unique number representing the trip | character |
| rideable_type | The type of bike being used for this ride | character |
| started_at | The trip’s start time in an ISO 8601-like format. | character |
| ended_at | The trip’s start time in an ISO 8601-like format. | character |
| start_station_name | The name of the station the trip started at. | character |
| start_station_id | The ID of the station the trip started at. | integer |
| end_station_name | The name of the station the trip started at. | character |
| end_station_id | The ID of the station the trip ended at. | integer |
| start_lat | The starting latitude | number |
| start_lng | The starting longitude | number |
| end_lat | The ending latitude | number |
| end_lng | The ending longitude | number |
| member_causal | Similar to usertype, but “member” or “causal” | chr |
Not only does it use different column names, but it also missing certain columns such as gender, birthyear, and tripduration. Additionally, it contains data that other data set don’t have such as the starting and ending longitude and latitude, and bike type. Finally, there are some data type inconsistencies.
If our current goal is to map the five data frames into one unified data frame for further analysis we will have to:
- Rename the columns we are keeping to the standard column names.
- Remove the unwanted columns.
- Add in missing columns filled will NA data.
- Calculate a
tripdurationcolumn. - Fix any data type inconsistencies.
The following will do just that.
|
|
Our 2020 Q1 data is now ready. The last step before mapping our data into a single data frame is to fix any
inconsistencies between data types. The only column of concern is trip_id which is stored as integers
in the 2019 data, but as characters in the 2020 data. We will convert all trip_ids from 2019 into characters.
|
|
Finally, we can combine the five data frames together using bind_rows() from the dplyr library.
|
|
Now that we have a single data frame containing the fully integrated bike trip data, we want to continue the process of cleaning our data by performing a descriptive analysis. This will help us get a better picture of our overall data set. It will also assist in the cleaning process by finding potential errors in our data. To perform our descriptive analysis we will systematically go through each column and investigate it for issues.
To begin, we will transform any empty strings in our data frame into NA types:
|
|
This will help make our data set more consistent overall.
Next, we will make sure that trip_id only contains unique values:
|
|
There are no duplicates, and we wouldn’t be able to rectify any missing trip ids, so we can move on to the start_time and end_time columns.
First, we should convert start_time and end_time data into POSIXct data types instead of characters so that they are easier to work with.
|
|
Next, let’s look for any NA or NULL rows in the start_time and end_timecolumns.
|
|
No rows are found to contain NA or NULL values. Now, we can make sure that there are no end times that are earlier than start times.
|
|
Unfortunately, there are 130 rows in which end_time is earlier than start_time.
We have to make a choice about how to handle this problem.
We could swap the end_time and start_time in the rows, but we would first have to make sure that the rest of the data they contain is valid.
Given the size of our dataset, I think it is safe simply to exclude these rows.
|
|
Now we can move onto tripduration. This column might be very important to answering our question, so its important that is it properly formatted.
Let’s recalculate tripduration using start_time and end_time, but store it in a new column called new_trip_duration:
|
|
Now, let’s investigate the qualities of this new_trip_duration to see if there are any problems.
|
|
The max, mean, and min values all return reasonable results. There are some outliers. For example, the longest trip is over three months long, which could be an error or indicate a missing or stolen bike. Additionally, some trips are only a few seconds long. This data isn’t inherently problematic, but we might consider removing it before we begin our analysis.
Next, we will take a look at the from_station_id and to_station_id columns. We start by checking it for NA or NULL values, and checking the max and min values:
|
|
Everything checks out. There are no NA or NULL values, and the min and max are identical for each (1 and 675).
Processing the Data
At this point, the original data sets we received have been integrated into a single data frame, and the original data has been cleaned. This is a good point to return to our business question, and consider what types of data we might be able to derive from our existing data to better complete our business task.
The question we are trying to answer is: How do annual members and casual riders differ in their use of Cyclistic bikes?
In our existing data, the usertype and tripduration fields are likely to provide some insight into the differences between annual members and casual riders. However, we can extract even more useful information from fields such as start_time and end_time. For example, we can determine which day of the week a trip starts and ends on to see if causal riders and annual members use their bikes during different times.
We will do this by storing each trip’s starting and ending weekday in the start_weekday and end_weekday columns:
|
|
We might also benefit from extracting the month, year, and quarter from the start_time and end_time fields and storing them as dedicated attributes.
|
|
If we want to be extra verbose, we could also convert the new_trip_duration field into different time scales. For example, instead of only having trip duration in seconds, we could calculate it in minutes, hours, and days:
|
|
With that complete, we are finished cleaning and processing our dataset. Our data should be of a reasonable enough quality to perform the analysis required of us.
We will save our cleaned dataset as an .RData file.
|
|
Performing the Analysis
Now that we have a workable data set we can begin the process of analysis. The question we are tasked with answering is: How do annual members and casual riders differ in their use of Cyclistic bikes? In other words, using the data we have we want to determine how the usage of the Cyclistic bike share service differs between annual members and casual riders. And, we want to use that analysis to provide insight to are stakeholders, in this case the marketing director and team, which will inform their marketing campaign.
Immediately, a few angles of analysis come to mind:
- How do the number of annual members compare to casual riders?
- Do different user types ride more on different days of the week?
- Does the average trip duration differ between annual members and casual riders?
- Do certain stations have a higher concentration of annual members or casual riders?
- Is there a difference between the time of day, or year, when annual members or casual riders use the service?
Before we attempt to gain insight into some of these questions, it is important to determine which subset of our data we will be using. A basic analysis of our user’s trip duration tells us a few things:
|
|
Firstly, we know that our data set contains some odd trip durations. There are trip durations which last many months, which may indicate either an error in the system or a bike which was missing or stolen, and there are trip durations which last no time at all (zero seconds, or are otherwise very short). Because we are examining the differences in behavior between customers groups who use the bike service, it is reasonable to exclude anomalous trip data (such as those that are very long and those that are very short).
Therefore, it is reasonable to limit our data set to trips that are at least one minute and at most forty-eight hours. We will store this data set in filtered_bike_data:
filtered_bike_data <- subset(bike_trip_data, duration_in_minutes > 1 & duration_in_minutes < 2880)
With our filtered data set, we can being our analysis in earnest. The first question to investigate is the ratio of annual member trips to casual riders. A good chart type to give an intuitive understanding of that ratio is a pie chart:
|
|
The result of our pie chart tells us that about 78% of all trips are taken by annual members. Meanwhile, casual riders, the group we are trying to convert into subscribers, make up only 22% of our group. Next, we should investigate, the days of the week annual members use the bike share service compared to casual riders.
|
|
From this bar chart we can compare the trends in each customer group by the weekday. We see that the number of casual riders increases on Friday, peaks on Saturday and Sunday, and then hits a low during the middle of the workweek. The annual rider usage is the inverse. Usage peaks during the middle of the workweek, and it sharply falls to a low on the weekends.
This indicates that some portion of the annual customers are likely using the bike share service as a a way to commute. While casual riders tend to use the bike share on the weekends. This might mean that casual riders have a higher number of tourists in the group, or that residents who are not subscribed only use the bikes when not working.
A recommendation is beginning to form. We know that just under a quarter of the total bike share customers are casual riders. And, we know that bike share usage by casual riders is lowest during the workweek and highest during the weekend. We should investigate further by checking how bike share usage differ on a month-to-month basis. After that, we might want to check how the duration of bike share usage differs between casual and annual riders. And then analyze stations to see if certain stations are more popular among casual riders.
First, let’s see how bike share usage differs in each group on a month-to-month basis:
|
|
This bar chart is quite revealing about the behavior of casual riders. Annual riders tend to use the bike share service consistently across the entire year. There is an obvious rise through Spring and peak in late Summer. However, casual riders use the service significantly less in the Winter months compared to annual riders. Like the annual riders their usage rises through Spring, peaks in Summer, and drops in Fall.
This indicates that if we were going to be advertising to them we would want to target these advertisements during the Spring and Summer months.
We are starting to get a good idea about the differences between annual members and casual riders. We know that both groups’ usage declines in the Fall and Winter, rises in the Spring, and peaks towards the end of the Summer. Furthermore, we know that casual riders tend to use the bikes less during the workweek and more on the weekend.
Next, we should do some basic investigation of the two groups’ trip durations and top starting and ending bike stations. To do this, we will create two new data frames, each containing only annual riders or casual riders:.
|
|
Next, we will compare the mean duration_in_minutes of each groups:
|
|
This gives us an interesting result. Despite both data sets being limited to trips with a minimum time of one minute, and a maximum time of two days, casual riders use their bikes for three times as long as annual members. Specifically, casual riders use bikes on average for around 40 minutes. Annual riders use their bikes for only 13 minutes on average.
Let’s check the two data sets to see if trips over one day in length is more common than in the other.
|
|
In our data, casual riders had 696 trips over a day in length while annual riders had only 315 trips lasting over a day. Let’s filter out all trips longer than a day from our data set, and reassess the mean duration_in_minutes
|
|
The values are basically the same: 12.7 minutes for annual riders and 39.4 minutes for casual riders. This tells us important information about how the two customer groups use the bike share. Annual riders use their bikes for less time, but perhaps more frequently, while casual riders use their bikes for longer, but make up a smaller quantity of the total trips taken.
Our last angle of analysis will be around bike stations. We will look at our two groups and compare their top stations for both starting and ending trips.
|
|
An analysis of the top ten stations for each customer group is quite revealing. The stations that casual customers use are all located in tourist heavy areas such as the South Loop, while annual rider’s top stations tend to be in the West loop which is a business district.
|
|
The geographic seperation Finally, let’s make some scatterplots to show the distribution of starting station trip totals between each customer group.
|
|